
The IFIC’s José Salt and Santiago González de la Hoz discuss the Big Data challenge at the LHC and how deep learning is being used in LHC experiments to extract knowledge.
Our image of Nature is given by the Standard Model (SM) which establishes that matter is constituted by quarks and leptons. There are four fundamental interactions, and three of them are, somehow, formulated in a unified way: strong, weak, and electromagnetism.
However, the SM cannot explain several relevant aspects observed and measured in particle physics and which, at the beginning of the 21st century, remained one of the most important issues: the origin of the mass of the elementary particles, namely, to find the predicted Higgs boson.
The Large Hadron Collider (LHC) programme launched two general purpose experiments to search for the Higgs boson and New Physics: ATLAS and CMS. Our group (the IFIC team) has been involved in ATLAS experiments since the early 1990s.
The data challenge
One of the great challenges of these experiments is the management and processing of a given amount of data coming from the High Energy Physics (HEP) experiment detectors. In previous HEP experiments based on accelerators (during the Low Energy Physics (LEP) era), the computing infrastructure started to become increasingly complex, so much so that the volume of data collected during the whole running period of experiments was of the order of around a hundred TB.
In the LHC era, we are faced with a very clear case of Big Data: in the LHC, 40 million collisions of bunches of protons take place every second, which is about 15 trillion collisions per year. For the ATLAS detector alone, one Mbyte of data is produced for every collision or 2,000 Tbytes (two PB) of data per year. On top of that, a similar amount of simulated data obtained from different theoretical models is needed to compare to the ‘real data’ that comes from experiments. It is then necessary to pass all these data through analysis programs in order to obtain physics results.
In addition to the problem of solving data management and processing (Big Data), we have also tackled the methodology to improve the sensitivity of our physics analysis procedures and to extract new knowledge from that huge amount of data through machine learning/deep learning. In the last part of this article, we will address the interesting progress that has been made here and outline a dedicated infrastructure used to achieve this goal.
The challenge of the Big Data in the LHC
By the beginning of this century, LHC experiments were able to search for the best solution for the following challenges:
- To address an unprecedented multi-petabyte data processing challenge;
- To provide a resilient infrastructure to more than 6,000 scientists from 200 universities and laboratories in 45 countries, around-the-clock; and
- To analyse the LHC data in search of new discoveries. At this time, GRID Distributed Computing was selected.
The GRID Distributed Computing solution became a reality and was implemented effectively around 2003; members of the LHC experiments could send in their jobs, which require the processing of big datasets from sites geographically distributed around the world. The fundamental idea of GRID is that the distributed system that involves this form of computing is seen from the user’s perspective as a large computer. An important aspect was to organise a co-ordinated system of sites/centres, LHC collaborations opted for a ‘tiered’ approach: Tier 0 at CERN, several regional sites (Tier-1), and Tier-2 centres with a very good connectivity between them. Thus, the Worldwide LHC Computing Grid (WLCG) project was born.
The WLCG1 is a collaboration composed of more than 170 computing centres distributed in 42 countries, connecting national and international grid infrastructures. The main goal of the WLCG is to build and maintain a distributed computing infrastructure to store, distribute, and analyse the data from the LHC experiments. The WLCG is supported by many grid projects, such as the LHC Computing Grid (LCG), the European Grid Initiative (EGI), the NorduGrid – Advanced Resource Connector (ARC), and Open Science Grid (OSG), amongst others.
ATLAS
The ATLAS experiment at CERN’s LHC uses a geographically distributed grid of approximately 150,000 cores continuously (250,000 cores at peak and over 1,000 million core hours per year) to simulate and analyse its data (ATLAS’s current total data volume is more than 260 PB).
The ATLAS Collaboration leads WLCG resource usage in terms of the number of jobs completed, the processed data volume, and the core hours used for High Energy. Since the start of LHC data taking, ATLAS has operated under conditions in which competition for computing resources among high-priority physics activities happen routinely. It will collect a factor of ten to 100 more data during the next three to five years. Scientific priorities in HEP present Big Data challenges requiring state-of-the art computational approaches and, therefore, serve as drivers of integrated computer and data infrastructure. To avoid potential shortfalls in projected LHC Grid resources, ATLAS is actively evaluating supercomputing-scale resources as an important supplement to keep up with the rapid pace of data collection and to produce simulated events for LHC experiments which are too complex and require enormous computing resources to produce them on the WLCG.
The need for simulation and analysis will overwhelm the expected capacity of WLCG computing facilities unless the range and precision of physics studies is curtailed. Even today, important analyses that require large, simulated samples are expected to have to wait for many months before WLCG existing grid resources will be able to provide the simulated data they need. In addition, some physical processes of interest at the LHC are nearly impossible to calculate on traditional grid resources because of extremely large computing requirements. Supercomputers offer unique opportunities to produce such datasets.
GRID computing and other computing paradigms
The LHC experiments have to handle data streams of PB/hour. The exploitation of LHC data is impossible without sophisticated computing tools. GRID computing fulfilled its mission for about a decade, practically alone, but soon other computing paradigms appeared that could coexist with GRID, such as volunteer computing, cloud computing, and HPC, which entered the game during the first and second Runs.
Higher luminosity is equivalent to higher data flow, so there is an increase on the horizon with the High Luminosity Large Hadron Collider (HL-LHC), and this represents a challenge for storage, network bandwidth, and processing power. As can be seen in Fig. 1, HL-LHC CPU estimations (baseline) show a factor of three to four shortfall to the flat budget model (+10% capacity/year) and a factor of five shortfall to today’s estimate in the storage on disk. At the HL-LHC, it will be required to increase the network bandwidth by a factor of ten.
There are a few ways that the CPU challenge can be addressed: to use HPCs, cloud computing, and High Level Trigger farms; to use fast instead of full simulation and thus speed up the Monte Carlo generators by a factor of two; and to run on GPUs; but one needs significant time and effort to adapt the software to the new architecture.
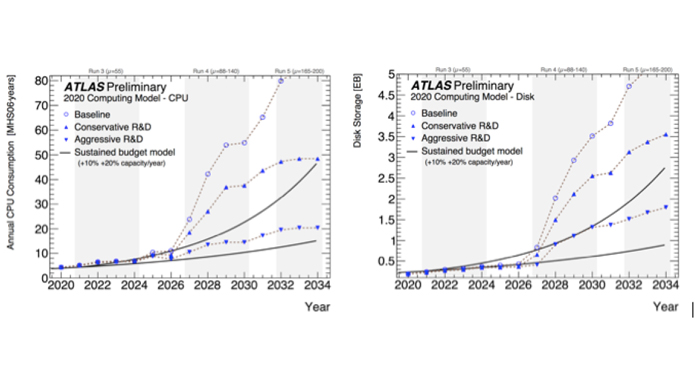
Approaches for solving the storage shortfall are:
- Increased investment in computing;
- New file formats;
- A reduction of data volumes; and
- Increased use of tape storage.
This last option slows down the workflow. This will be the major impact on how we will deploy the infrastructure: data-lakes with centres connected to sites with large storage capacity, use of caches, smaller data, more use of the network, etc.
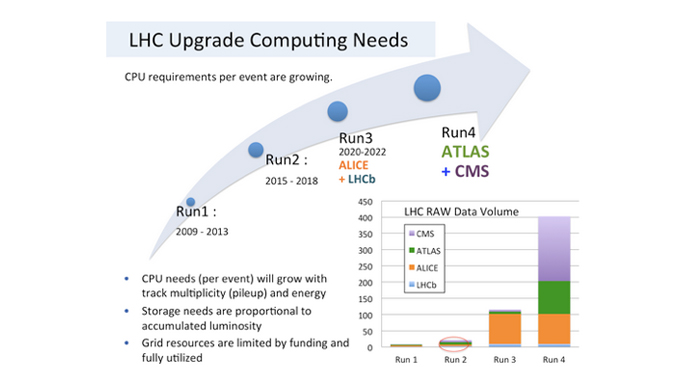
If the resource demands during the first two Runs were very high, we currently have prospects for growth for Run 3 and for HL-LHC (2026) which are of an order of magnitude higher, as can be seen in Fig. 2.
This circumstance has led to a search for resources from different sources. Although there are efforts in the use of cloud computing in centres participating in ATLAS, here we are going to focus on HPC resources as many countries already have HPC (Supercomputing) centres and are investing heavily in such programmes. At the Spanish level and at the IFIC (Valencia) in particular,2 we have taken the necessary steps to be able to use these resources and have the incremental CPU time that we need to fulfil our commitments within the ATLAS collaboration.
Since it is not possible to install the edge services on HPC premises, we opted to install a dedicated ARC-CE and interact with the HPC login and transfer nodes using ssh commands. ATLAS software, including a partial CVMFS snapshot, is packed into a container singularity image to overcome the network isolation for the HPC worker nodes and to reduce the software requirements.
Lusitania and MareNostrum HPC resource integration in the ATLAS production system started in April 2018 in a collaboration between IFIC and PIC. Since then, we have been granted periods where we have been able to exploit several million hours of HPC resources. In 2020, the MareNostrum 4 HPC was fully integrated into the ATLAS computing framework. During that year, the MareNostrum 4 HPC was responsible for 30% of the total contribution to ATLAS’s computing by the Spanish cloud. Among all the different types of computing, however, the MareNostrum 4 HPC only contributed to the simulation effort.3
Data management and a Big Data catalogue for ATLAS
Data management and data access are two of the main activities that are carried out continuously in LHC experiments to be able to process them.
RAW data straight from the detector are reconstructed, resulting in both Event Summary Data (ESD) and Analysis Object Data (AOD). The former incorporates enough information for detector performance studies, while the latter, much reduced, contains only information about physical reconstructed objects useful for physics analyses. In addition, filtered versions of ESD and AOD, derived data formats DPDs, can be created by the different physics groups to select events of their interest.
The data distribution policy states that RAW data is transferred from CERN to the ten Tier ones, keeping three replicas. Reconstructed data, ESD/AOD, is distributed to Tier ones and Tier twos. A large fraction of this data is recorded on disk in order to perform analyses for the understanding of the detector response.
Users can always submit a job to the Grid to analyse data; the job will be running at the (Tier two) site where the data are located. In addition, users can request to replicate some data to the Tier two site they belong to in order to access the data in a local mode. For this purpose, the Data Transfer Request web Interface (DaTRI) of the PANDA web portal was created. The DaTRI is coupled to the ATLAS Distributed Data Management (DDM) system to move the data between sites.
The storage in ATLAS is organised using space tokens. These are controlled through the DDM system and are associated with a path to a Storage Element (SE).
Event Index
The ATLAS experiment at the CERN LHC accelerator started taking data in 2009 and collected almost 25 billion physics triggers (events), plus calibration data and simulated events. The procedures to obtain physical quantities of interest for the final analyses imply the creation of additional versions of the same events, some of which replace older versions, and in the generation of reduced sets of selected events for each particular analysis.
Groups of statistically equivalent events are stored in files on disk or on tape; in turn, files are grouped into datasets that can be hierarchically assembled into containers. The distributed data management system4 is used to keep track of each file, dataset, and container, including their properties (metadata) and replica locations, as well as to manage the data movements between different storage sites and the CPU farms where the data are processed and analysed.
A previous implementation of a similar tool, the ‘Tag Database’, was used during LHC Run One (2009 to 2013), with somewhat different use cases and record contents. Despite large efforts over several years, its performance remained below expectation and by the end of 2012 the decision was made to explore a more updated approach. Currently, several ATLAS groups have joined their efforts to create a better Event Catalogue system. One of these groups is the IFIC GRID Tier two group.
The Event Index was designed for this primary use: the quick and direct event selection and retrieval. However, it immediately became clear that the same system could fulfil several other tasks, such as checking the correctness and completeness of data processing procedures, detecting duplicated events, studying trigger correlations, and derivation stream overlaps.5
The latest developments are aimed to optimise storage and operational resources in order to accommodate the higher amount of data produced by ATLAS, which is expected to increase in the future with a prediction of 35 billion new, real events per year in Run three, and 100 billion at the HL-LHC. A new prototype based on HBase event tables and queries through Apache Phoenix has been tested and shows encouraging results. A good table schema was designed and the basic functionality is ready.
We are now working towards improved performance and better interfaces, aiming to have the refactored system in operation well in advance of the start of Run three in 2022. According to our expectations, this system will be able to withstand the data production rates foreseen for LHC Run four and beyond.

Physics results in LHC could not be possible without computing
ATLAS detectors (electromagnetic calorimeter, hadronic calorimeter, muon chambers, etc.) are specialised subprojects with a long duration and they go hand-in-hand throughout the scientific lifetime of the experiment. Usually, these projects cover its construction, maintenance, and operation. They also have R&D programmes for technological updating. In the same way, the LHC computing has a similar development: to build and operate a computer infrastructure distributed by the different ATLAS WLCG centres.
The computer equipment and human resources are parts of an ambitious project whose objective is precisely to provide the infrastructure and the necessary tools to carry out the physics analysis, calibrations, etc. and that is reflected in the physics results.
Computing enables the rapid delivery of the physics results; a huge amount of data comes from detectors in experiments placed around 100 metres underground. These data are stored, processed, and distributed worldwide by the network and, using the GRID, the events are available in GRID sites in about two hours and the final analysis of selected events is performed by the physics groups. One of the most relevant contributions was the discovery of the Higgs boson in the CMS and ATLAS experiments, and it was therefore recognised in the official announcement of said discovery on 4 July, 2012.
Our Tier two centre has acted as one cog in the wider computer gear in order to achieve this global objective. Since Run one, IFIC was involved in the Spanish Federated Tier two (ES-ATLAS-T2) and consequently in the Iberian ATLAS cloud, providing computing resources to the ATLAS Collaboration.2
Role of AI/ML in the improvement of the achievements of LHC experiments
To now focus on a somewhat different aspect, which is also based on the use of the collected data: obtaining knowledge from these data by applying machine learning/deep learning techniques.
Artificial Intelligence is being applied in several aspects of High Energy Physics, in particular in LHC experiments: in trigger and data acquisition systems, in computing challenges, event simulation, reconstruction, detector performance, physics analysis, and so on. Focusing on physics analysis activities and event simulation we can give the following examples:
- Improvement in the sensitivity of the experiment in several physics analysis. In particular, our group has improved the invariant mass reconstruction of ttbar events by applying ML techniques (supervised and unsupervised)6; and
- LHC analysis-specific datasets obtained by applying DL methods: using Generative Adversarial Networks (GAN)7 or Variational Autoencoders, teams can investigate the possibility of creating large amounts of analysis-specific simulated LHC events at limited computing cost.
For these studies, we have used libraries of open source ML such as TensorFLow, SCIKit Learn, Keras, and others, which allow us to implement the improvements in an agile and versatile way. In addition, our group has been able to utilise ARTEMISA, a very advanced infrastructure available in our institute.
ARTEMISA8 stands for ‘ARTificial Environment for ML and Innovation in Scientific Advanced Computing’ and it is located at the IFIC Computing Center. It is a new piece of equipment which is devoted to AI techniques such as ML and Big Data and it operates continuously thanks to its batch system. Users can develop and test their programs and send their Jobs to 23 machines with GPU processors.9 ARTEMISA is open to all the scientific groups affiliated to any Spanish public university or research institution.
Boosting the physics analysis by applying ML methods
Physics analysis in HEP in general and in the LHC experiment, in particular, continues to use data analysis tools with statistical methods at their heart. By the 1980s, several experiments started to use Artificial Neural Networks for classifying the events collected during data taking runs. Other methods were also developed using the fundamentals of Machine Learning (Decision Trees, Random Forest, etc.).10
Problems in HEP are of high dimensionality and this requires a powerful process of data reduction. The number of variables or features are very high. Physicists have used a wide variety of ML techniques including ANN, Support Vector Machines (SVM), genetic algorithms, Random Forest, and BDT (in the TMVA software package). Their capabilities were limited when the dimensionality of data became so large.
DL began to emerge around 2012, when a convergence of techniques enabled very large neural networks to be trained, and which quickly overtook the previous state-of-the-art.11
The use of deep learning in several ATLAS physics analyses have shown better achievements, for instance in Higgs studies which gave better results than those obtained by traditional methods. In most of cases, the results obtained by applying these ML methods, which use a large amount of CPU time, showed improvements.
Paving the road for the future
Several actions geared towards making progress in advanced computing have been reported in this article. All are necessary, but perhaps they are not enough to face the challenges of the future. Computing evolves very quickly, and while we can try to predict the challenges that will emerge in the coming four or five years, we cannot foresee things beyond that period.
Computing resources such as GRID, cloud, HPC, etc. are heterogeneous in order to be as powerful as possible, and AI/ML infrastructures are emerging to complement the performance of several activities. Meanwhile, physics analysis facilities are incorporating accelerator technologies to perform analysis by applying ML/DL techniques.
In Valencia, IFIC has developed the cornerstones to build the next computing framework that will allow us to tackle the increasingly ambitious scientific goals.
References
2) S. González de la Hoz et al, ‘Computing activities at the Spanish Tier-1 and Tier-2s for the ATLAS experiment towards the LHC Run3 and High-Luminosity periods’, EPJ Web of Conferences 245, 07027 (2020). https://doi.org/10.1051/epjconf/202024507027
3) C. Acosta, J. del Peso, E. Fullana, S. González de la Hoz, A. Pacheco, J. Salt, J. Sánchez, ‘Exploitation of the MareNostrum 4 HPC using ARC-CE’. Submitted to vCHEP2021 (internal reference vCHEP2021-210226-1319)
4) Berisits, M., Beermann, T., Berghaus, F. et al, ‘Rucio. Scientific Data Management’, Computing and Software for Big Science (2019) 3:11; https://doi.org/10.1007/341781-019-0026-3
5) Dario Barberis et al. ‘The ATLAS Event Index: A Big Data catalogue for all ATLAS experiment events’. ATLAS note: ATL-COM-SOFT-2020-073, to be submitted to Computing and Software for Big Science
6) J. Salt, S. González de la Hoz, M. Villaplana, S. Campos, on behalf of the ATLAS Collaboration. ‘Comparison of different ML methods applied to the classification of events with ttbar in the final state at the ATLAS experiment’. Proceedings of the Conference Connecting The Dots/Intelligent Trackers 2019 (CTD/WIT 2019): ATL-COM-SOFT-2019-019
7) B. Hashemi, N. Amin, K. Datta, D. Olivito, M.Pierini arXiv:1901.05282V1
8) https://artemisa.ific.uv.es/web/
9) All the batch machines contain an NVIDIA GPU Volta V100 to support AI-oriented algorithms
10) Dan Guest, Kyle Cranmer and Daniel Whiteson, ‘Deep Learning and its application to LHC Physics’, arXiv:1806.11484V, June 2018
11) LeCun Y, Bengio Y, Hinton G., Nature 521:436 (2015)
José Salt
Santiago González de la Hoz
The Instituto de Física Corpuscular (IFIC)
jose.salt@ific.uv.es
sgonzale@ific.uv.es
Tweet @IFICorpuscula
https://webific.ific.uv.es/web/en
Please note, this article will also appear in the sixth edition of our quarterly publication.





