
The EU-funded DAEMON project has developed several practical solutions to integrate AI into mobile network architectures and help automate the management of complex communication systems.
The DAEMON1 project is a 36-month Research and Innovation Action (RIA) funded by the European Union H2020 framework programme under call H2020-ICT-2018-20, topic ICT-52-2020 ‘5G PPP – Smart Connectivity beyond 5G.’ The project focuses on 6G mobile networks and aims to help them meet the high expectations in terms of support for very diverse classes of service, near-zero latency, apparent infinite capacity, and 100% reliability and availability. Meeting such ambitious performance targets requires growing the already substantial complexity of mobile network architectures, making automated management a mandatory requirement for 6G systems.
Within this context, the main goal of the DAEMON project is developing and implementing innovative and pragmatic approaches to NI design that enable a high-performance, sustainable, and extremely reliable zero-touch network system. Specifically, the DAEMON project intends to depart from the current hype around Artificial Intelligence (AI) as the silver bullet for any mobile network management task. It intends to realise a systematic integration of varied Machine Learning (ML) models into network architectures that ensure an effective design and operation of Network Intelligence (NI) in 6G systems.
In this article, we outline two representative NI solutions that were devised and implemented within the context of the project and demonstrated at the 2023 Mobile World Congress held in Barcelona, Spain.
Compute-aware radio scheduling
The virtualisation of radio access networks (RANs), based hitherto on monolithic appliances over ASICs, will become the spearhead of next-generation mobile network systems beyond 5G. Initiatives such as the O-RAN alliance2 explore novel solutions that disaggregate inflexible Base Stations (BSs) into virtualised components that are much more adaptable and cost-efficient. In the O-RAN vision, Distributed Unit (DU) components represent a critical element, as they host physical layer (PHY) functions that have very strict latency requirements in shared edge clouds where predictable computation times are hard to achieve.
Within the context of the DAEMON project, we first demonstrated the risks of running DUs in shared edge clouds where they compete for resources: generic computing (or task) schedulers employed in cloud systems are not designed for inter-dependencies between DU tasks, which causes head-of-line blocking and ultimately leads to suddenly deteriorating performance due to missed processing deadlines for one or multiple DUs. The problem forces operators to largely over-dimension edge resources to avoid the problem. We argue, however, that a more sensible solution can be developed based on in-depth understanding of the PHY pipeline and of the requirements of each step. Following this approach, we devised and implemented a novel architecture of a DU, which we name Nuberu, which is specifically engineered for 4G LTE and 5G New Radio (NR) workloads that are virtualised over clouds of shared resources with non-deterministic capacity. Nuberu’s design has one goal: to guarantee every Transmission Time Interval (TTI) a minimum viable subframe (MVSF) that provides the smallest set of signals required to preserve user synchronisation while maximising throughput during shortages of computing resources.
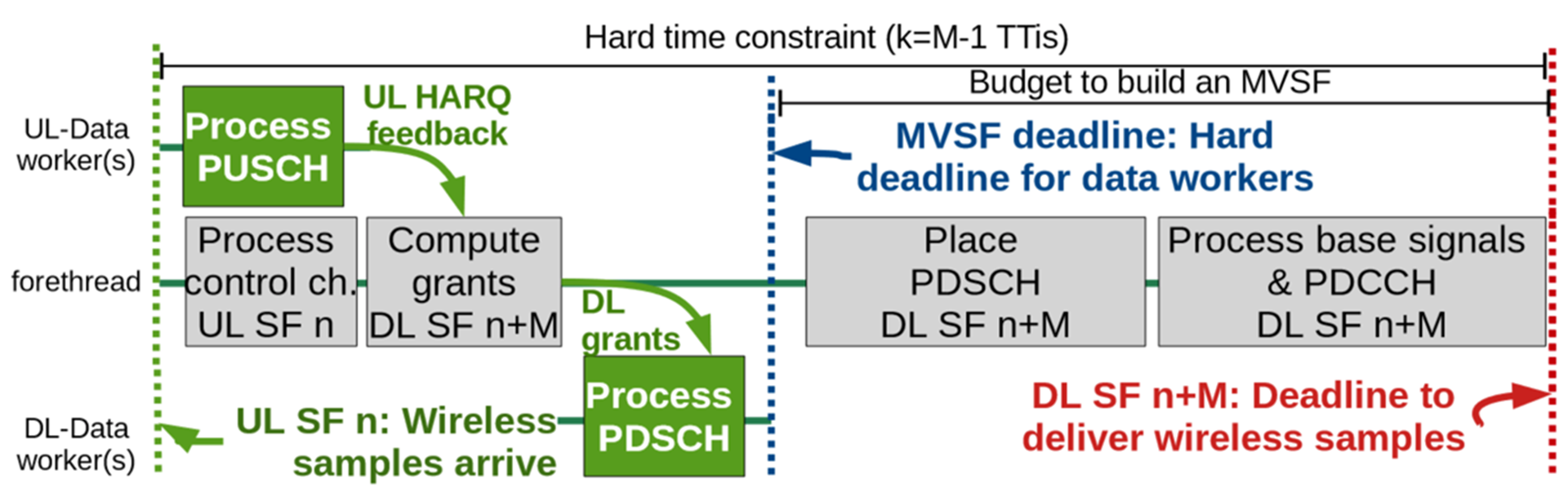
Specifically, we organise the data processing pipeline for each job’s data task into separate threads as shown in Fig. 1 and are listed next.
- DU forethread: In charge of (i) building the MVSF; and (ii) coordinating the remaining DU data workers (middle of Fig. 1);
- DL-Data DU workers: One or more threads in charge of the bulk of downlink processing tasks (processing the transport blocks (TBs) carried by the physical downlink shared channel, or PDSCH) (bottom of Fig. 1); and
- UL-Data DU workers: One or more threads in charge of the bulk of the tasks to process TBs carried by the physical uplink shared channel (PUSCH) (top of Fig. 1).
We then set up a hard deadline (Φ), for every job (n — blue line in Fig. 1) upon which an MVSF is compiled even if data workers have not finished. Note that, as shown before, basic MVSF tasks in charge of the forethread (such as computing grants or building PDCCH) require little or deterministic processing time, which can be estimated a priori to calculate Φ, = n + M − Ƭ, where Ƭ is the time required to compile an MVSF plus the transportation delay (Ȣms). The challenge is to decouple and adapt data processing tasks in a way such that the performance loss caused by computing fluctuations is minimised.
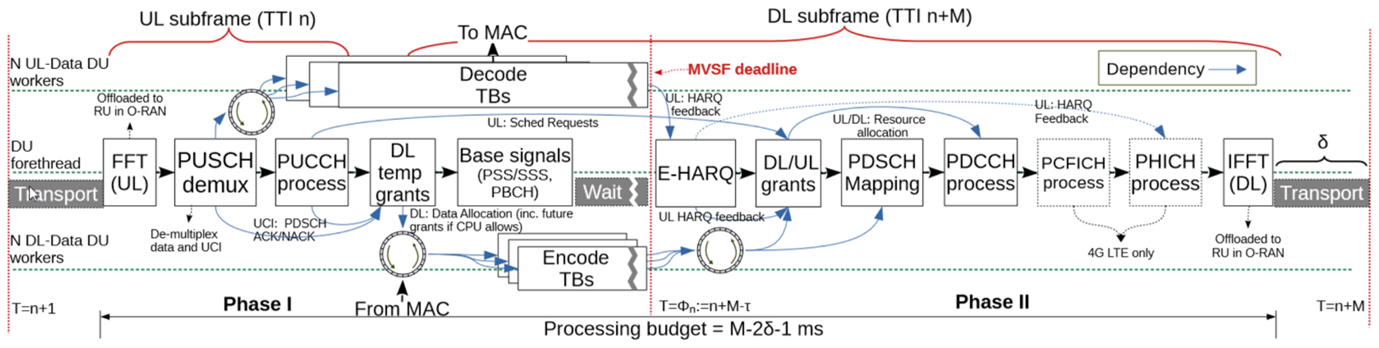
Nuberu achieves this through a dedicated design, where the forethread is responsible for building an MVSF and exploiting the work of data workers to maximise performance during shortages of computing resources. Full details about the architecture can be found in the technical paper describing the complete solution.3
We presented Nuberu at the ACM MobiCom 2021 conference,3 where we demonstrated how it overcomes the limitations of legacy DU designs, preserving high throughput irrespective of the available computing capacity and providing elasticity upon computing fluctuations.
Running AI in programmable user planes
Machine Learning (ML) models have become key enablers of automation in networking scenarios with applications in areas such as traffic classification, quality of service (QoS) prediction, and routing optimisation. In the traditional software-defined network (SDN) paradigm, the ML models are trained and executed in the control plane. However, such models do not operate at line rate and hence do not meet the very low latency requirements typical of many and varied next-generation network functions.
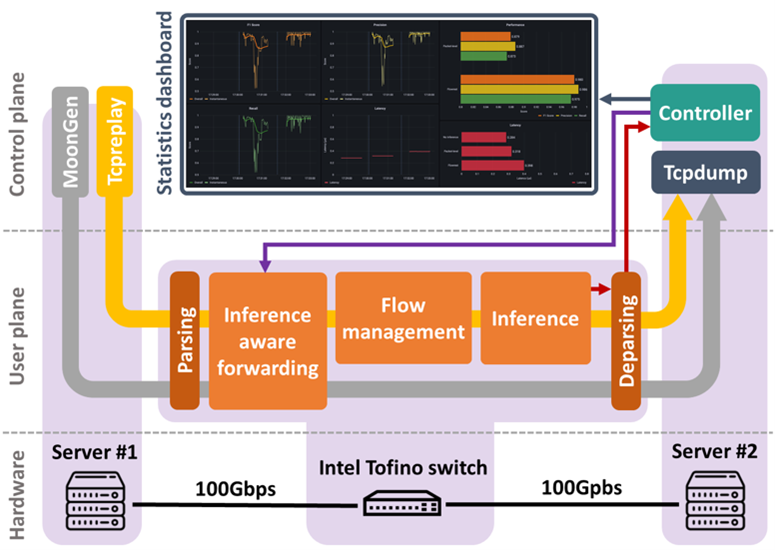
In the DAEMON project, we exploit off-the-shelf programmable data planes, like Intel Tofino ASICs,4 and domain-specific languages, like P4,5 to achieve low-latency and high-throughput inference in networks. Embedding ML models into user plane hardware is in fact a challenging task, especially in the case of programmable switches, owing to their high constraints in terms of memory, support for mathematical operations, and the amount of allowed per-packet operations. Previous works3,4,5 have shown the potential of in-switch inference based on Decision Tree (DT) and Random Forest (RF) models. Yet, due to the constraints above, existing approaches fall short in at least three aspects. Firstly, most solutions employ only, and do not use stateful flow-level features such as inter-arrival times and flow counts that are essential for an effective inference in challenging use cases. Second, they support limited scalability regarding ML model complexity and the difficulty of the classification tasks that can be effectively handled. Lastly, many solutions are only tested in emulation environments and are unsuitable for real hardware deployment.
In the DAEMON project, we address several of these challenges by designing Flowrest,6 a practical framework that can run RF models at flow level in real-world programmable switches, hence enabling the embedding of large RF models into production-grade hardware, for challenging inference tasks on individual traffic flows and at line rate. Specifically, Flowrest removes barriers that affect similar previous proposals, such as reliance on stateless packet-level features only, limited scalability in terms of ML model complexity, or tests bounded to emulation environments.
We implemented Flowrest in a 100-Gbps real-world testbed with Intel Tofino switches. Tests involving tasks of unprecedented complexity show how our model can improve accuracy by up to 39% over previous approaches to implement RF models in real-world equipment. All results were first presented and demonstrated during the IEEE INFOCOM 2023 conference,6 and won the Best Demo Awards at IEEE NetSoft 2023 conference.
References
- DAEMON – Network intelligence for aDAptive and sElf-Learning MObile Networks
- A. Garcia-Saavedra and X. Costa-Perez, “O-RAN: Disrupting the Virtualised RAN Ecosystem,” IEEE Commun. Stand. Mag., pp. 1–8, 2021, doi: 10.1109/MCOMSTD.101.2000014
- G. Garcia-Aviles, A. Garcia-Saavedra, M. Gramaglia, X. Costa-Perez, P. Serrano, A. Banchs, Nuberu: reliable RAN virtualisation in shared platforms. ACM MobiCom 2021, New Orleans, USA, Oct 2021
- Intel, “Tofino Programmable Ethernet Switch ASIC,” 2016
- P. Bosshart, D. Daly, G. Gibb, M. Izzard, N. McKeown, J. Rexford, C. Schlesinger, D. Talayco, A. Vahdat, G. Varghese, and D. Walker, ‘P4: Programming protocol-independent packet processors,’ SIGCOMM Computer Communication Review, vol. 44, no. 3, jul 2014
- A.T.-J. Akem, M. Gucciardo, M. Fiore, Flowrest: Practical Flow-Level Inference in Programmable Switches with Random Forests, IEEE INFOCOM 2023, New York, USA, May 2023

This document has been produced in the context of the
DAEMON Project. The research leading to these results
has received funding from the European Union Horizon
2020 research and innovation programme under grant
agreement No. 101017109
Please note, this article will also appear in the sixteenth edition of our quarterly publication.




